1 📰 Newsies (multi-class classification)
This notebook contains the code samples found in Chapter 3, Section 6 of Deep Learning with R. Note that the original text features far more content, in particular further explanations and figures: in this notebook, you will only find source code and related comments.
In the previous section we saw how to classify vector inputs into two mutually exclusive classes using a densely-connected neural network. But what happens when you have more than two classes?
In this section, we will build a network to classify Reuters newswires into 46 different mutually-exclusive topics. Since we have many classes, this problem is an instance of “multi-class classification”, and since each data point should be classified into only one category, the problem is more specifically an instance of “single-label, multi-class classification”. If each data point could have belonged to multiple categories (in our case, topics) then we would be facing a “multi-label, multi-class classification” problem.
1.1 The Reuters dataset
We will be working with the Reuters dataset, a set of short newswires and their topics, published by Reuters in 1986. It’s a very simple, widely used toy dataset for text classification. There are 46 different topics; some topics are more represented than others, but each topic has at least 10 examples in the training set.
Like IMDB and MNIST, the Reuters dataset comes packaged as part of Keras. Let’s take a look right away:
Like with the IMDB dataset, the argument num_words = 10000 restricts the data to the 10,000 most frequently occurring words found in the data.
We have 8,982 training examples and 2,246 test examples:
length(train_data)
[1] 8982length(test_data)
[1] 2246As with the IMDB reviews, each example is a list of integers (word indices):
train_data[[1]]
[1] 1 2 2 8 43 10 447 5 25 207 270 5 3095
[14] 111 16 369 186 90 67 7 89 5 19 102 6 19
[27] 124 15 90 67 84 22 482 26 7 48 4 49 8
[40] 864 39 209 154 6 151 6 83 11 15 22 155 11
[53] 15 7 48 9 4579 1005 504 6 258 6 272 11 15
[66] 22 134 44 11 15 16 8 197 1245 90 67 52 29
[79] 209 30 32 132 6 109 15 17 12Here’s how you can decode it back to words, in case you are curious:
word_index <- dataset_reuters_word_index()
reverse_word_index <- names(word_index)
names(reverse_word_index) <- word_index
decoded_newswire <- sapply(train_data[[1]], function(index) {
# Note that our indices were offset by 3 because 0, 1, and 2
# are reserved indices for "padding", "start of sequence", and "unknown".
word <- if (index >= 3) reverse_word_index[[as.character(index - 3)]]
if (!is.null(word)) word else "?"
})
cat(decoded_newswire)
? ? ? said as a result of its december acquisition of space co it expects earnings per share in 1987 of 1 15 to 1 30 dlrs per share up from 70 cts in 1986 the company said pretax net should rise to nine to 10 mln dlrs from six mln dlrs in 1986 and rental operation revenues to 19 to 22 mln dlrs from 12 5 mln dlrs it said cash flow per share this year should be 2 50 to three dlrs reuter 3The label associated with an example is an integer between 0 and 45: a topic index.
train_labels[[1]]
[1] 31.2 Preparing the data
We can vectorize the data with the exact same code as in our previous example:
To vectorize the labels, there are two possibilities: we could just cast the label list as an integer tensor, or we could use a “one-hot” encoding. One-hot encoding is a widely used format for categorical data, also called “categorical encoding”. For a more detailed explanation of one-hot encoding, you can refer to Chapter 6, Section 1. In our case, one-hot encoding of our labels consists in embedding each label as an all-zero vector with a 1 in the place of the label index, e.g.:
Note that there is a built-in way to do this in Keras, which you have already seen in action in our MNIST example:
one_hot_train_labels <- to_categorical(train_labels)
one_hot_test_labels <- to_categorical(test_labels)
1.3 Building our network
This topic classification problem looks very similar to our previous movie review classification problem: in both cases, we are trying to classify short snippets of text. There is however a new constraint here: the number of output classes has gone from 2 to 46, i.e. the dimensionality of the output space is much larger.
In a stack of dense layers like what we were using, each layer can only access information present in the output of the previous layer. If one layer drops some information relevant to the classification problem, this information can never be recovered by later layers: each layer can potentially become an “information bottleneck”. In our previous example, we were using 16-dimensional intermediate layers, but a 16-dimensional space may be too limited to learn to separate 46 different classes: such small layers may act as information bottlenecks, permanently dropping relevant information.
For this reason we will use larger layers. Let’s go with 64 units:
model <- keras_model_sequential() %>%
layer_dense(units = 64, activation = "relu", input_shape = c(10000)) %>%
layer_dense(units = 64, activation = "relu") %>%
layer_dense(units = 46, activation = "softmax")
There are two other things you should note about this architecture:
You end the network with a dense layer of size 46. This means for each input sample, the network will output a 46-dimensional vector. Each entry in this vector (each dimension) will encode a different output class.
The last layer uses a
softmaxactivation. You saw this pattern in the MNIST example. It means the network will output a probability distribution over the 46 different output classes: that is, for every input sample, the network will produce a 46-dimensional output vector, whereoutput[[i]]is the probability that the sample belongs to classi. The 46 scores will sum to 1.
The best loss function to use in this case is categorical_crossentropy. It measures the distance between two probability distributions: in our case, between the probability distribution output by our network, and the true distribution of the labels. By minimizing the distance between these two distributions, we train our network to output something as close as possible to the true labels.
1.4 Validating our approach
Let’s set apart 1,000 samples in our training data to use as a validation set:
val_indices <- 1:1000
x_val <- x_train[val_indices,]
partial_x_train <- x_train[-val_indices,]
y_val <- one_hot_train_labels[val_indices,]
partial_y_train = one_hot_train_labels[-val_indices,]
Now let’s train our network for 20 epochs:
Let’s display its loss and accuracy curves:
plot(history)
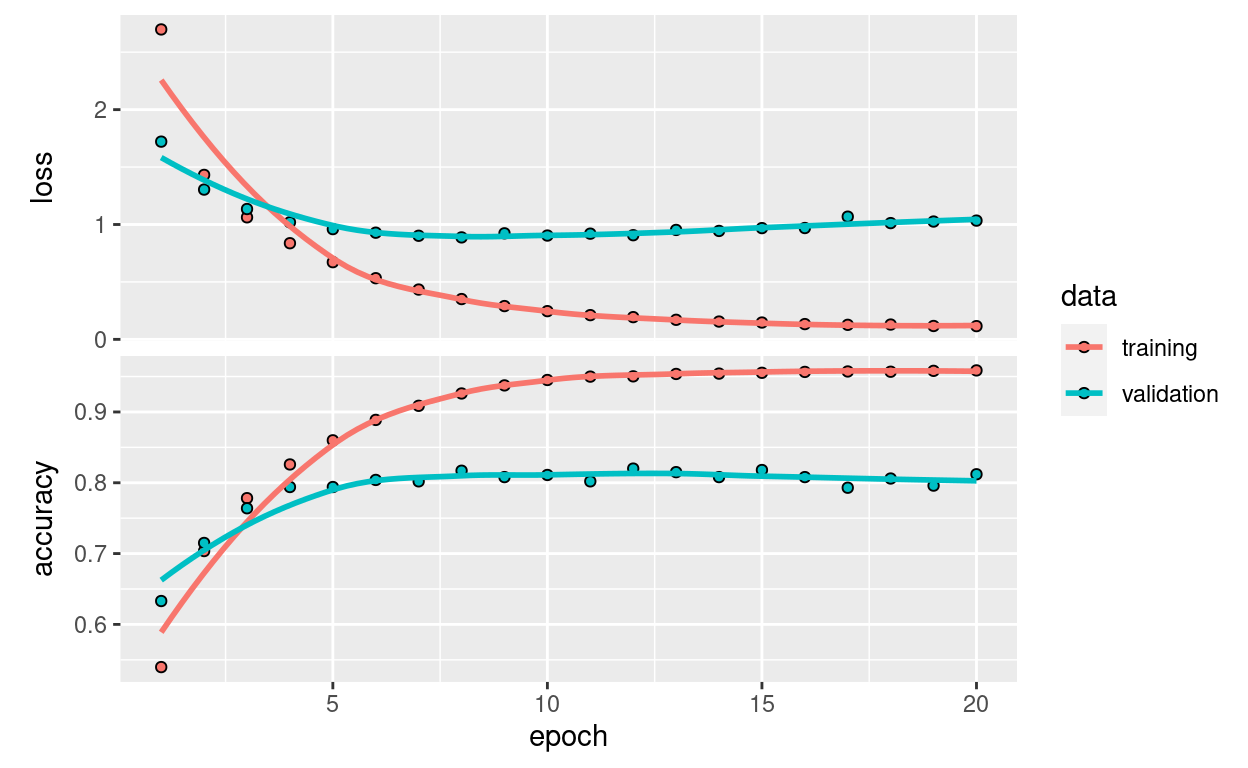
The network begins to overfit after nine epochs. Let’s train a new network from scratch for nine epochs and then evaluate it on the test set.
model <- keras_model_sequential() %>%
layer_dense(units = 64, activation = "relu", input_shape = c(10000)) %>%
layer_dense(units = 64, activation = "relu") %>%
layer_dense(units = 46, activation = "softmax")
model %>% compile(
optimizer = "rmsprop",
loss = "categorical_crossentropy",
metrics = c("accuracy")
)
history <- model %>% fit(
partial_x_train,
partial_y_train,
epochs = 9,
batch_size = 512,
validation_data = list(x_val, y_val)
)
results <- model %>% evaluate(x_test, one_hot_test_labels)
results
loss accuracy
0.9791760 0.7831701 Our approach reaches an accuracy of ~78%. With a balanced binary classification problem, the accuracy reached by a purely random classifier would be 50%, but in our case it is closer to 19%, so our results seem pretty good, at least when compared to a random baseline:
test_labels_copy <- test_labels
test_labels_copy <- sample(test_labels_copy)
length(which(test_labels == test_labels_copy)) / length(test_labels)
[1] 0.20347281.5 Generating predictions on new data
We can verify that the predict method of our model instance returns a probability distribution over all 46 topics. Let’s generate topic predictions for all of the test data:
Each entry in predictions is a vector of length 46:
dim(predictions)
[1] 2246 46The coefficients in this vector sum to 1:
sum(predictions[1,])
[1] 1The largest entry is the predicted class, i.e. the class with the highest probability:
which.max(predictions[1,])
[1] 41.6 A different way to handle the labels and the loss
We mentioned earlier that another way to encode the labels would be to preserve their integer values. The only thing this approach would change is the choice of the loss function. The previous loss, categorical_crossentropy, expects the labels to follow a categorical encoding. With integer labels, you should use sparse_categorical_crossentropy:
This new loss function is still mathematically the same as categorical_crossentropy; it just has a different interface.
1.7 On the importance of having sufficiently large intermediate layers
We mentioned earlier that since our final outputs were 46-dimensional, we should avoid intermediate layers with much less than 46 hidden units. Now let’s try to see what happens when we introduce an information bottleneck by having intermediate layers significantly less than 46-dimensional, e.g. 4-dimensional.
model <- keras_model_sequential() %>%
layer_dense(units = 64, activation = "relu", input_shape = c(10000)) %>%
layer_dense(units = 4, activation = "relu") %>%
layer_dense(units = 46, activation = "softmax")
model %>% compile(
optimizer = "rmsprop",
loss = "categorical_crossentropy",
metrics = c("accuracy")
)
model %>% fit(
partial_x_train,
partial_y_train,
epochs = 20,
batch_size = 128,
validation_data = list(x_val, y_val)
)
Our network now seems to peak at ~71% test accuracy, a 8% absolute drop. This drop is mostly due to the fact that we are now trying to compress a lot of information (enough information to recover the separation hyperplanes of 46 classes) into an intermediate space that is too low-dimensional. The network is able to cram most of the necessary information into these 8-dimensional representations, but not all of it.
1.8 Further experiments
- Try using larger or smaller layers: 32 units, 128 units…
- We were using two hidden layers. Now try to use a single hidden layer, or three hidden layers.
1.9 Wrapping up
Here’s what you should take away from this example:
- If you are trying to classify data points between N classes, your network should end with a dense layer of size N.
- In a single-label, multi-class classification problem, your network should end with a
softmaxactivation, so that it will output a probability distribution over the N output classes. - Categorical crossentropy is almost always the loss function you should use for such problems. It minimizes the distance between the probability distributions output by the network, and the true distribution of the targets.
- There are two ways to handle labels in multi-class classification:
- Encoding the labels via “categorical encoding” (also known as “one-hot encoding”) and using
categorical_crossentropyas your loss function. - Encoding the labels as integers and using the
sparse_categorical_crossentropyloss function.
- Encoding the labels via “categorical encoding” (also known as “one-hot encoding”) and using
- If you need to classify data into a large number of categories, then you should avoid creating information bottlenecks in your network by having intermediate layers that are too small.