Learning Objectives
- Exploratory Data Analysis (cont’d):
- Pairs plot to show correlation between variables and avoid multicollinearity (see 8.2 Many predictors in a model)
- Logistic Regression seen as an evolution of techniques
- Linear Model to show simplest multivariate regression, but predictions can be outside the binary values.
- Generalized Linear Model uses a logit transformation to constrain the outputs to being within two values.
- Generalized Additive Model allows for “wiggle” in predictor terms.
- Maxent (Maximum Entropy) is a presence-only modeling technique that allows for a more complex set of shapes between predictor and response.
1 Explore (cont’d)
Let’s load R packages and data from previous Explore session last time for your species.
librarian::shelf(
DT, dplyr, dismo, GGally, here, readr, tidyr)
select <- dplyr::select # overwrite raster::select
options(readr.show_col_types = F)
dir_data <- here("data/sdm")
pts_env_csv <- file.path(dir_data, "pts_env.csv")
pts_env <- read_csv(pts_env_csv)
nrow(pts_env)
[1] 1000datatable(pts_env, rownames = F)
Let’s look at a pairs plot (using GGally::ggpairs()) to show correlations between variables.
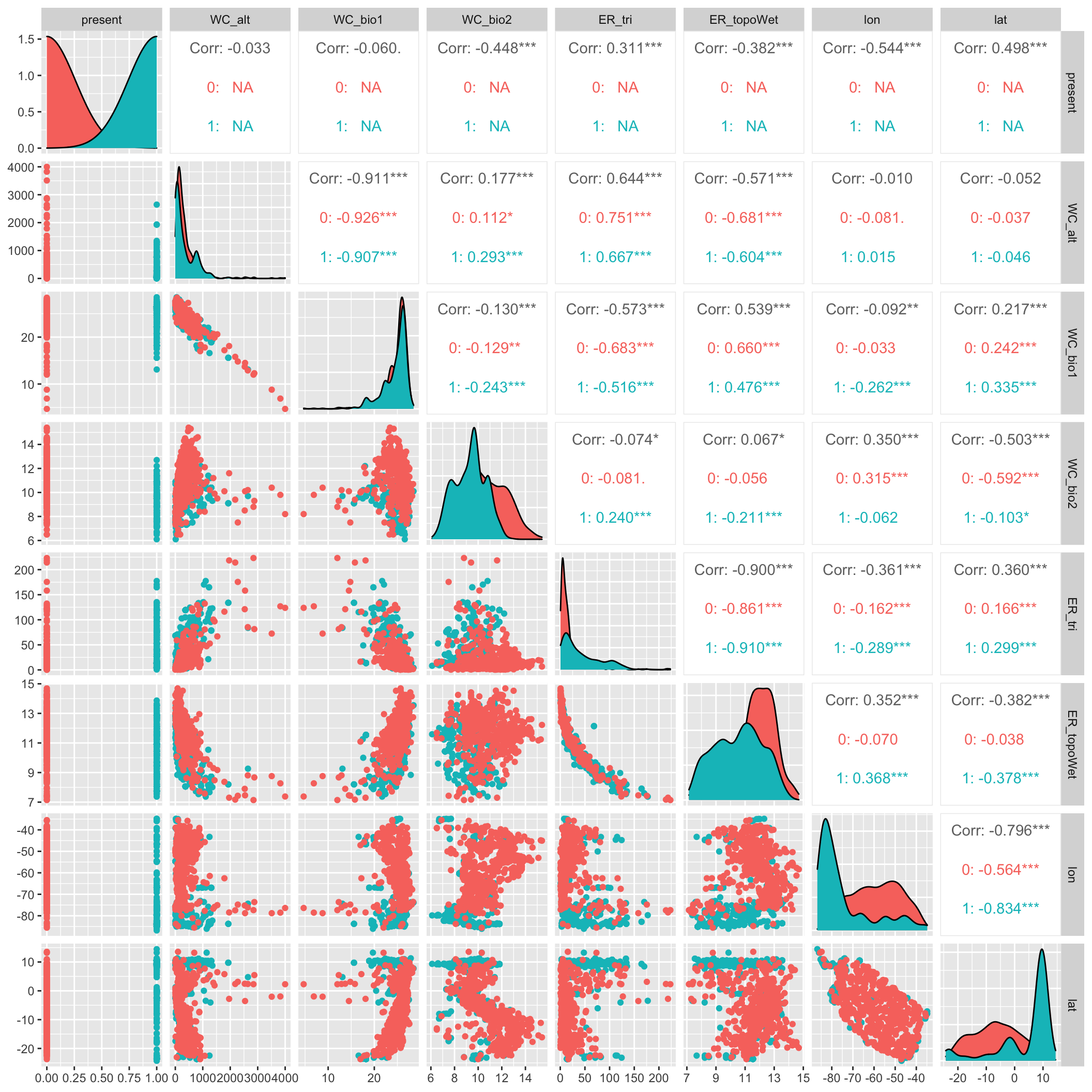
Figure 1: Pairs plot with present color coded.
2 Logistic Regression
We’ll work up to the modeling workflow using multiple regression methods along the way.
Figure 2: Full model workflow with split, fit, predict and evaluate process steps.
2.1 Setup Data
Let’s setup a data frame with only the data we want to model by:
- Dropping rows with any NAs. Later we’ll learn how to “impute” values with guesses so as to not throw away data.
- Removing terms we don’t want to model. We can then use a simplified formula \(present \sim .\) to predict \(present\) based on all other fields in the data frame (i.e. the \(X\)`s in \(y \sim x_1 + x_2 + ... x_n\)).
# setup model data
d <- pts_env %>%
select(-ID) %>% # remove terms we don't want to model
tidyr::drop_na() # drop the rows with NA values
nrow(d)
[1] 9862.2 Linear Model
Let’s start as simply as possible with a linear model lm() on multiple predictors X to predict presence y using a simpler workflow.
Figure 3: Simpler workflow with only fit and predict of all data, i.e. no splitting.
Call:
lm(formula = present ~ ., data = d)
Residuals:
Min 1Q Median 3Q Max
-1.11910 -0.25328 0.01387 0.16584 0.97373
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.867e+00 3.443e-01 17.040 < 2e-16 ***
WC_alt -1.124e-03 7.788e-05 -14.430 < 2e-16 ***
WC_bio1 -1.776e-01 1.324e-02 -13.411 < 2e-16 ***
WC_bio2 -4.385e-02 8.499e-03 -5.160 2.99e-07 ***
ER_tri -7.664e-04 7.740e-04 -0.990 0.322
ER_topoWet -7.783e-02 1.649e-02 -4.720 2.70e-06 ***
lon -1.131e-02 1.257e-03 -8.999 < 2e-16 ***
lat 1.187e-02 2.362e-03 5.025 5.99e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3383 on 978 degrees of freedom
Multiple R-squared: 0.546, Adjusted R-squared: 0.5427
F-statistic: 168 on 7 and 978 DF, p-value: < 2.2e-16[1] -0.4400731 1.1482654range(y_true)
[1] 0 1The problem with these predictions is that it ranges outside the possible values of present 1 and absent 0. (Later we’ll deal with converting values within this range to either 1 or 0 by applying a cutoff value; i.e. any values > 0.5 become 1 and below become 0.)
2.3 Generalized Linear Model
To solve this problem of constraining the response term to being between the two possible values, i.e. the probability \(p\) of being one or the other possible \(y\) values, we’ll apply the logistic transformation on the response term.
\[ logit(p_i) = \log_{e}\left( \frac{p_i}{1-p_i} \right) \] We can expand the expansion of the predicted term, i.e. the probability \(p\) of being either \(y\), with all possible predictors \(X\) whereby each coeefficient \(b\) gets multiplied by the value of \(x\):
\[ \log_{e}\left( \frac{p_i}{1-p_i} \right) = b_0 + b_1 x_{1,i} + b_2 x_{2,i} + \cdots + b_k x_{k,i} \]
# fit a generalized linear model with a binomial logit link function
mdl <- glm(present ~ ., family = binomial(link="logit"), data = d)
summary(mdl)
Call:
glm(formula = present ~ ., family = binomial(link = "logit"),
data = d)
Deviance Residuals:
Min 1Q Median 3Q Max
-3.0195 -0.5288 -0.0519 0.3889 2.7508
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 38.5403456 3.1998188 12.045 < 2e-16 ***
WC_alt -0.0082441 0.0007861 -10.487 < 2e-16 ***
WC_bio1 -1.2759384 0.1263666 -10.097 < 2e-16 ***
WC_bio2 -0.4671871 0.0880062 -5.309 1.10e-07 ***
ER_tri -0.0025306 0.0074738 -0.339 0.734915
ER_topoWet -0.4933633 0.1633552 -3.020 0.002526 **
lon -0.0923616 0.0116910 -7.900 2.78e-15 ***
lat 0.0737912 0.0208015 3.547 0.000389 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1366.74 on 985 degrees of freedom
Residual deviance: 659.77 on 978 degrees of freedom
AIC: 675.77
Number of Fisher Scoring iterations: 6[1] 0.0004979806 0.9939078317Excellent, our response is now constrained between 0 and 1. Next, let’s look at the term plots to see the relationship between predictor and response.
# show term plots
termplot(mdl, partial.resid = TRUE, se = TRUE, main = F, ylim="free")
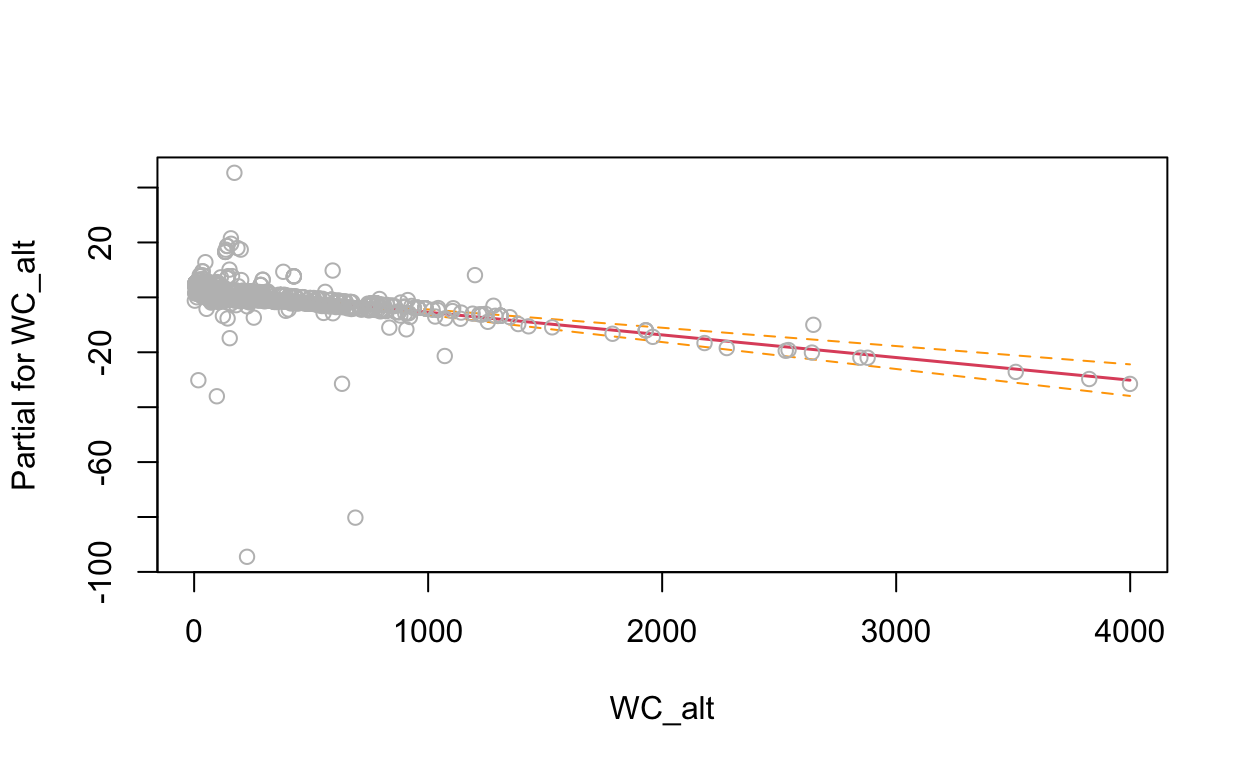
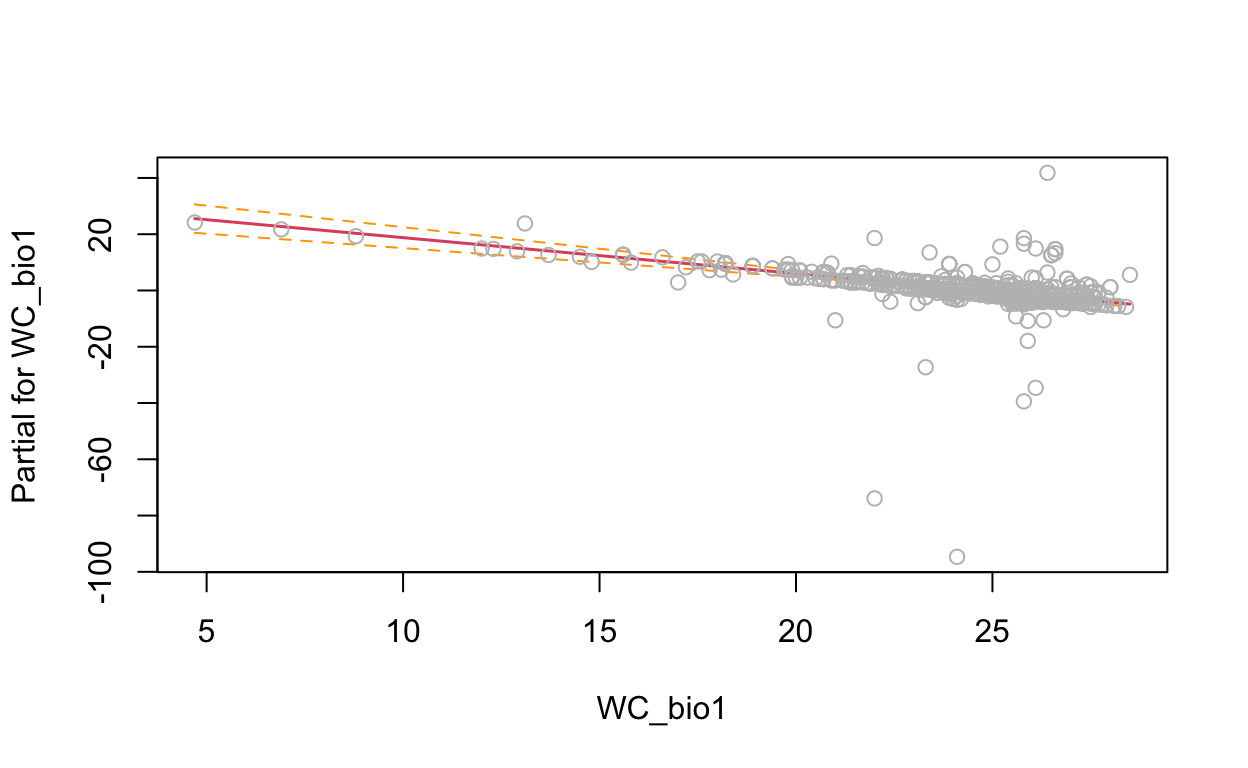
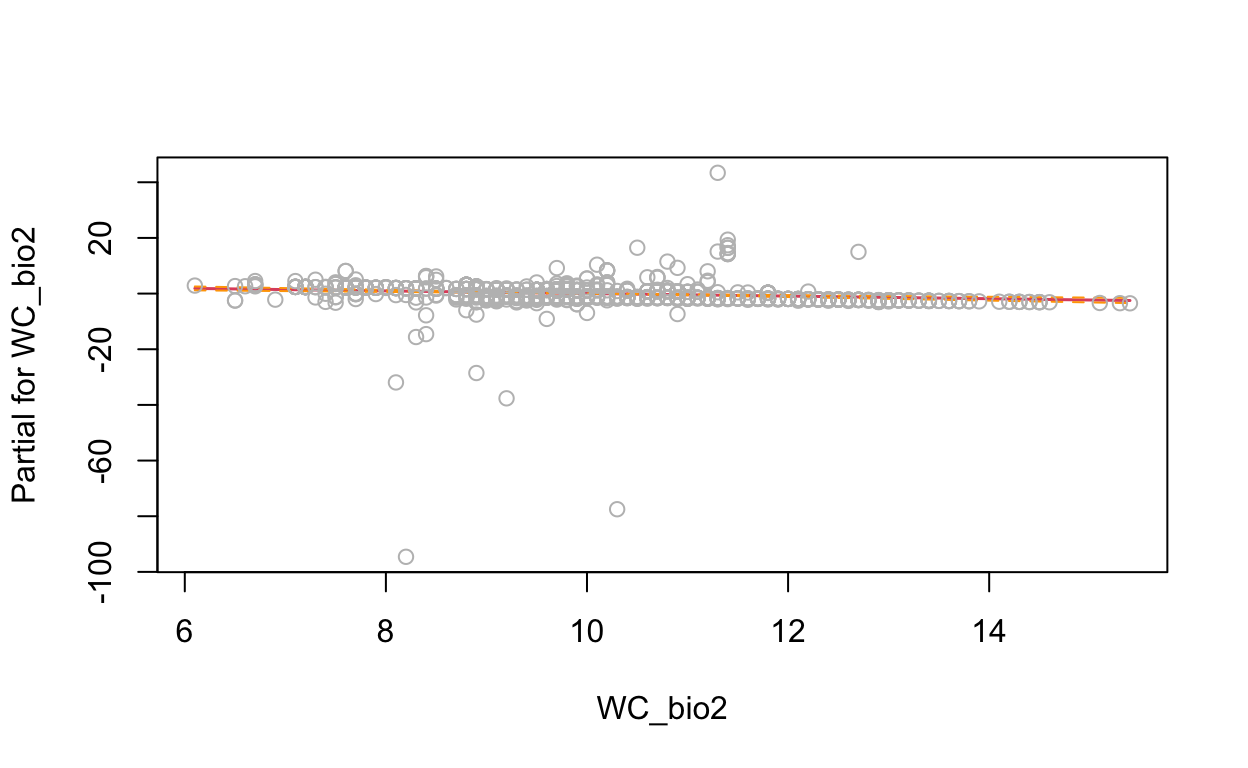
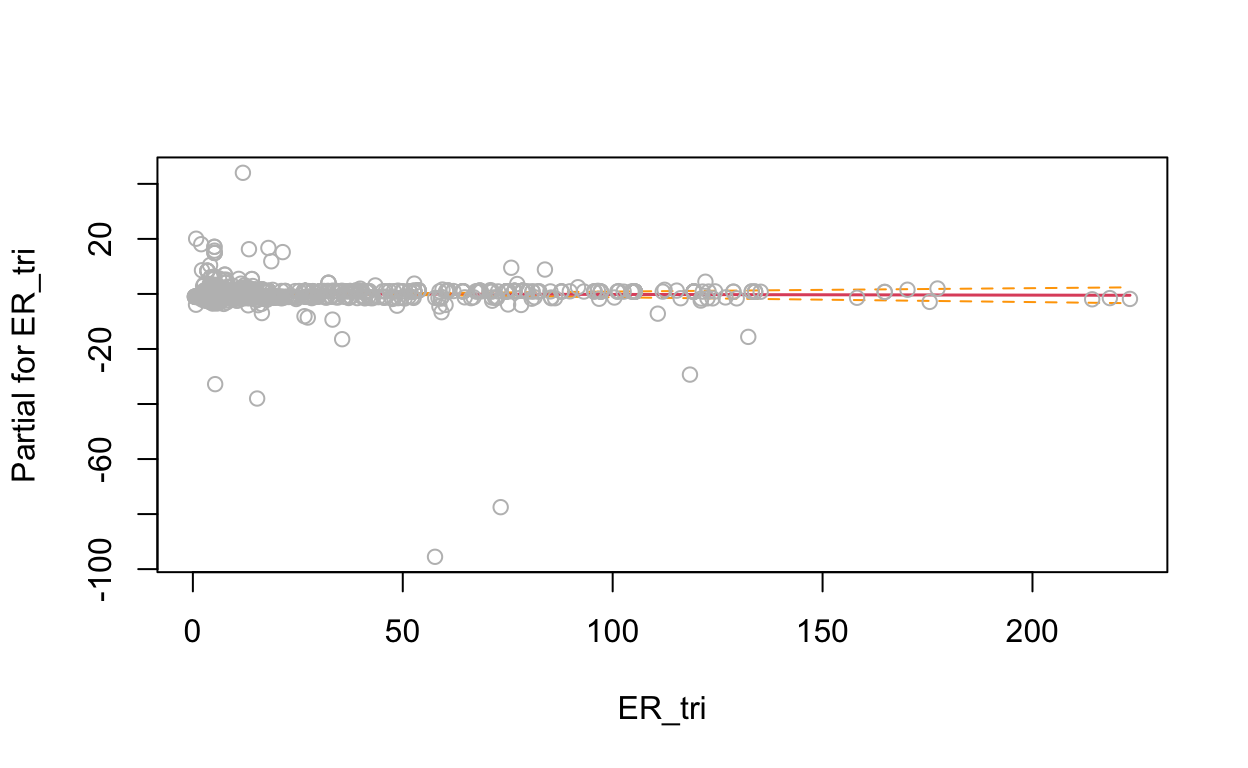
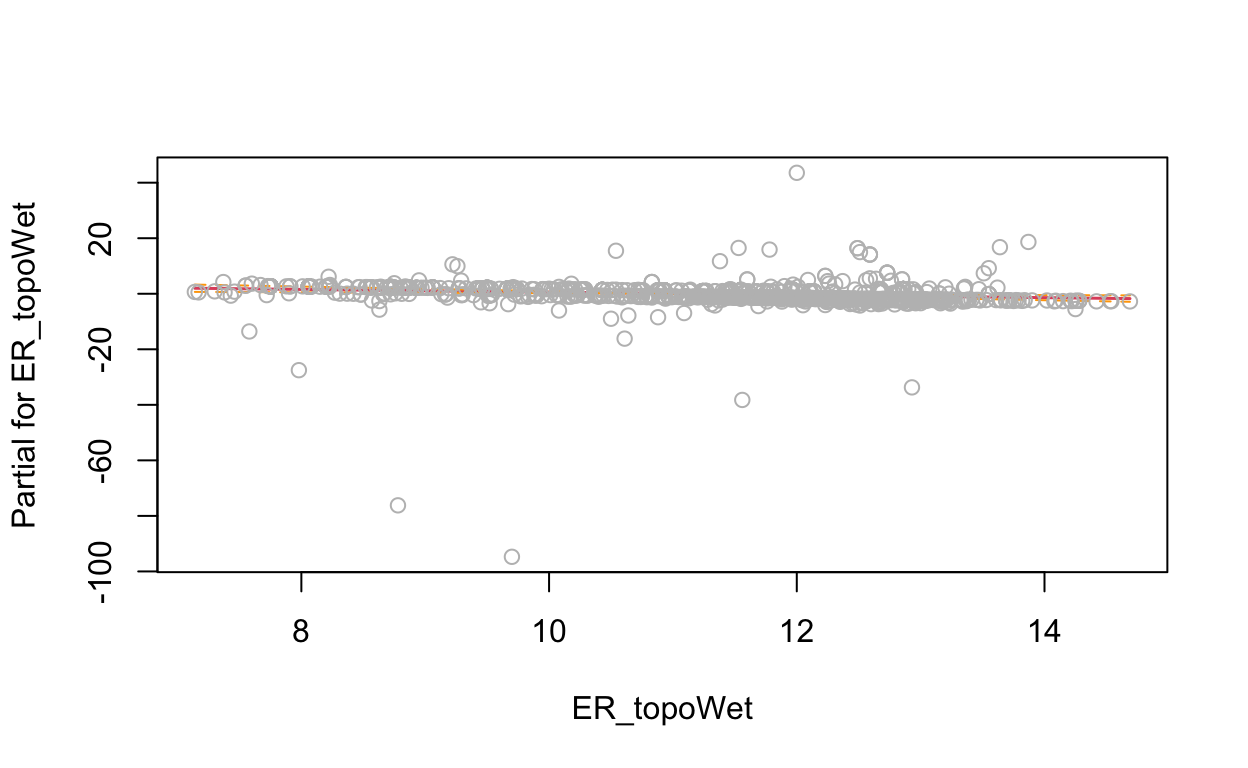
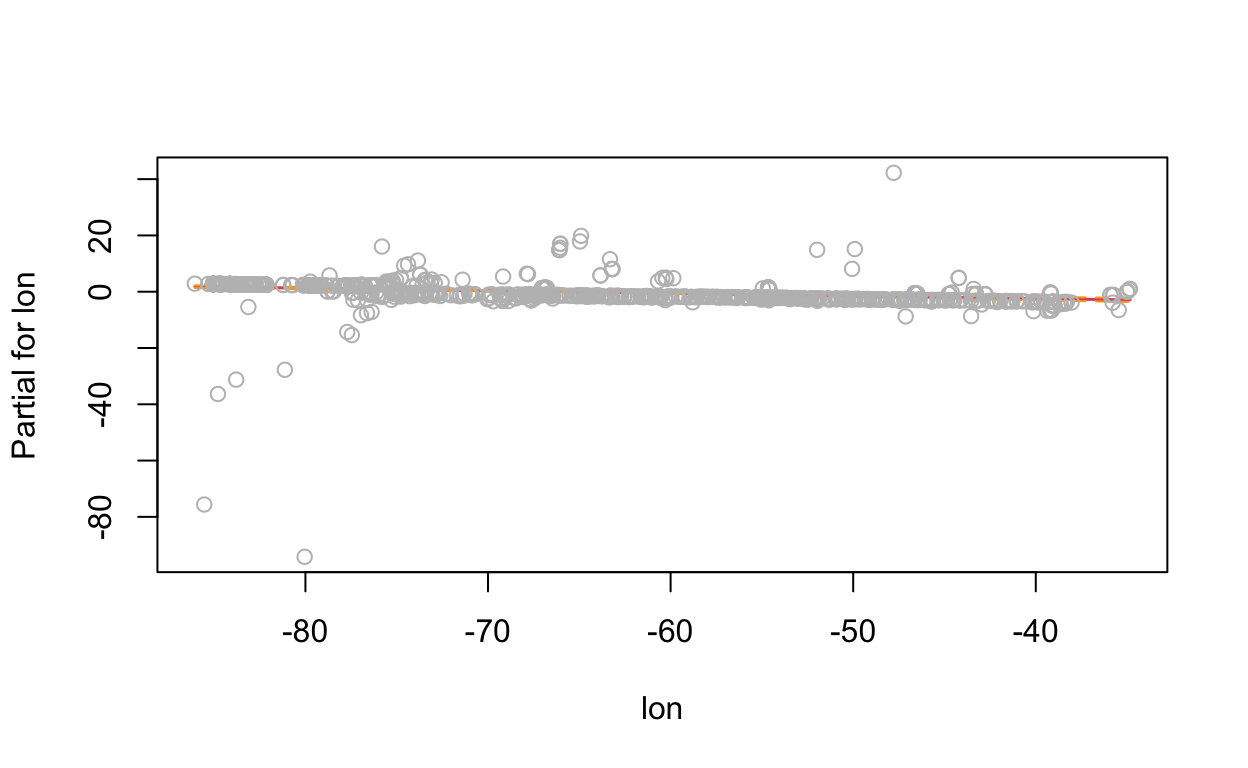
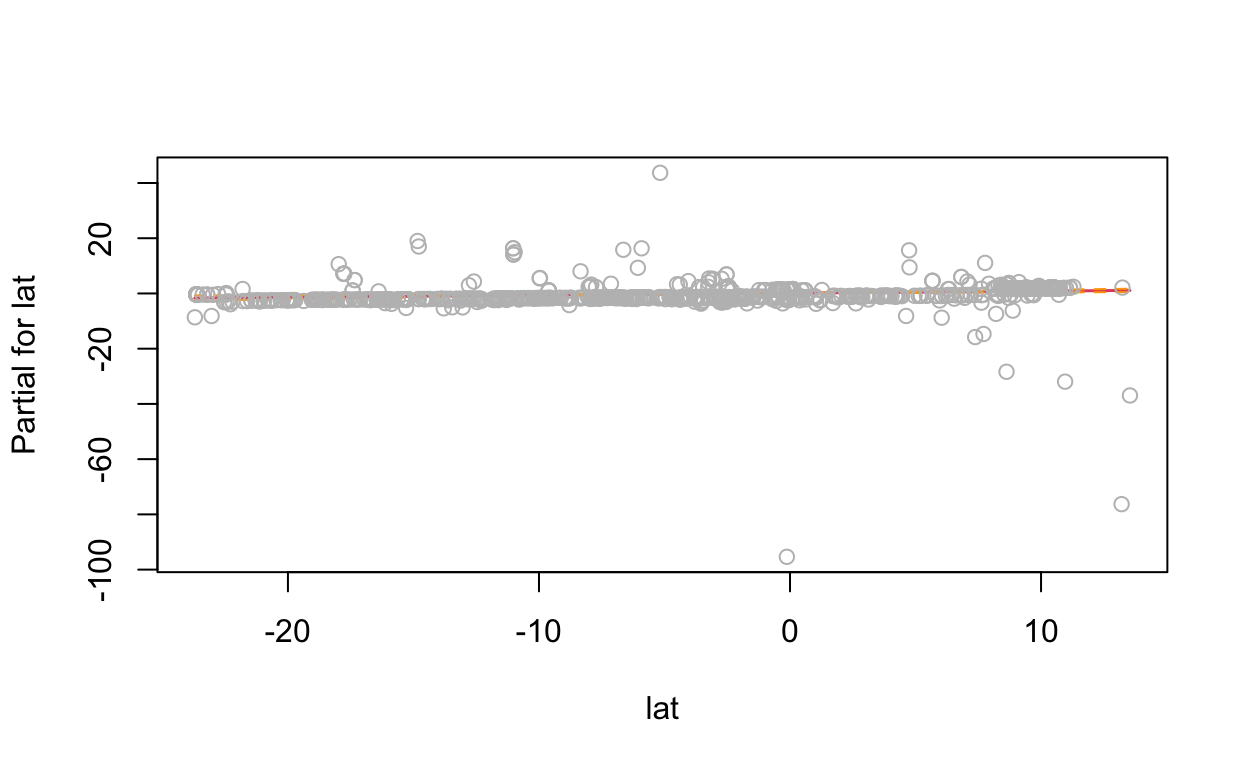
2.4 Generalized Additive Model
With a generalized additive model we can add “wiggle” to the relationship between predictor and response by introducing smooth s() terms.
librarian::shelf(mgcv)
# fit a generalized additive model with smooth predictors
mdl <- mgcv::gam(
formula = present ~ s(WC_alt) + s(WC_bio1) +
s(WC_bio2) + s(ER_tri) + s(ER_topoWet) + s(lon) + s(lat),
family = binomial, data = d)
summary(mdl)
Family: binomial
Link function: logit
Formula:
present ~ s(WC_alt) + s(WC_bio1) + s(WC_bio2) + s(ER_tri) + s(ER_topoWet) +
s(lon) + s(lat)
Parametric coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.1895 0.2361 -0.803 0.422
Approximate significance of smooth terms:
edf Ref.df Chi.sq p-value
s(WC_alt) 7.571 8.192 32.305 0.000103 ***
s(WC_bio1) 1.000 1.000 7.390 0.006558 **
s(WC_bio2) 4.511 5.416 26.341 0.000191 ***
s(ER_tri) 1.888 2.366 0.513 0.724252
s(ER_topoWet) 3.375 4.283 5.931 0.222731
s(lon) 7.034 8.015 74.638 < 2e-16 ***
s(lat) 8.682 8.961 44.773 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
R-sq.(adj) = 0.711 Deviance explained = 64.9%
UBRE = -0.44276 Scale est. = 1 n = 986# show term plots
plot(mdl, scale=0)
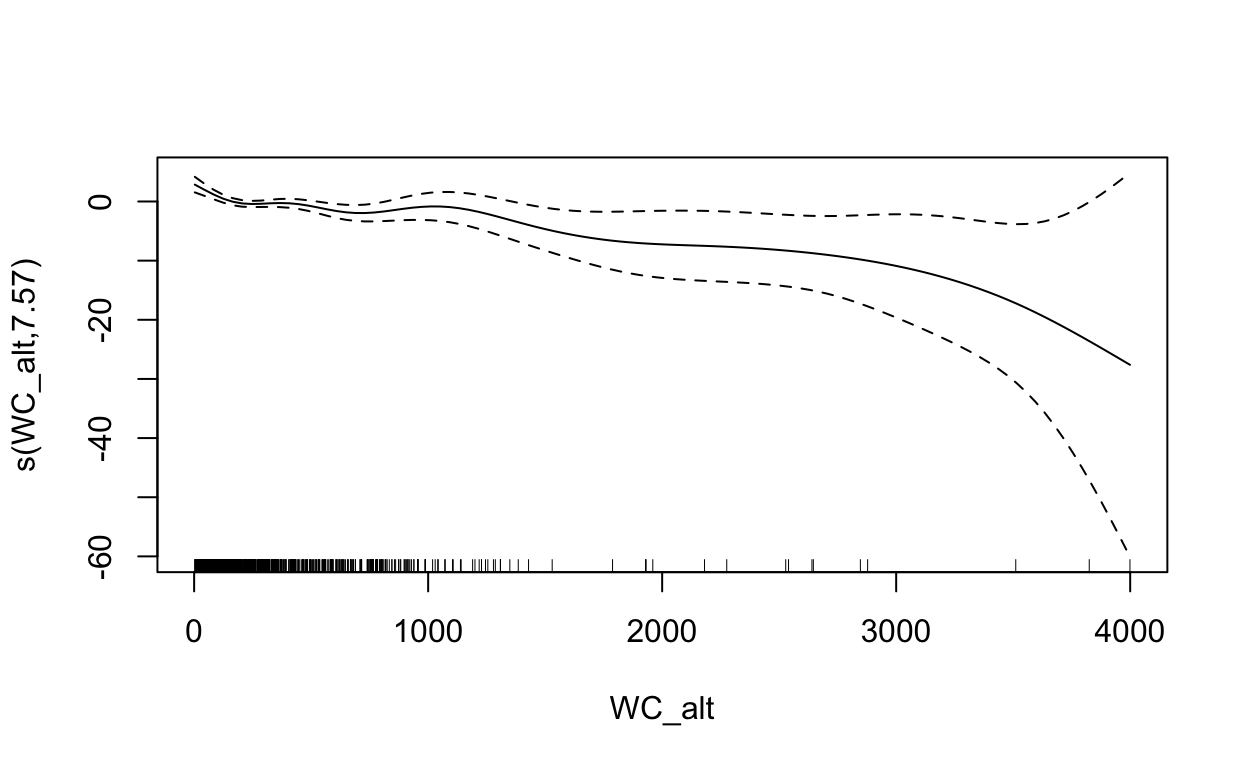
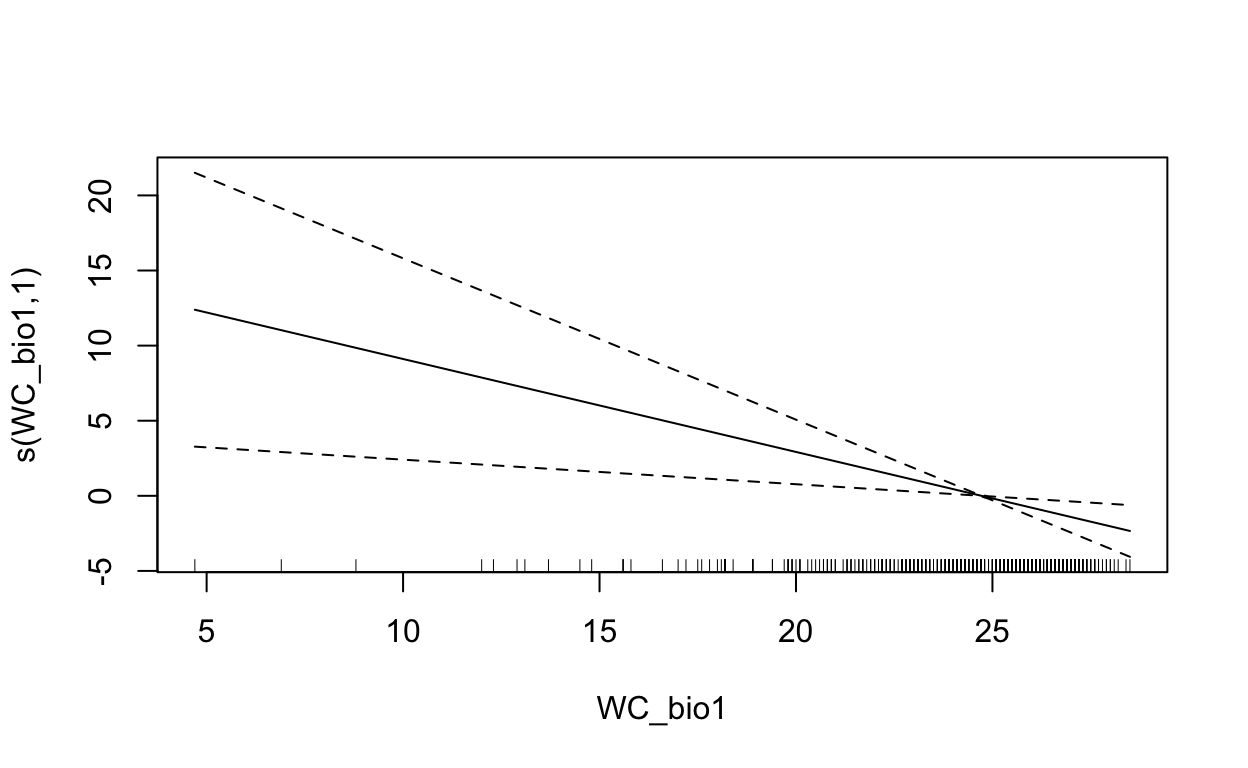
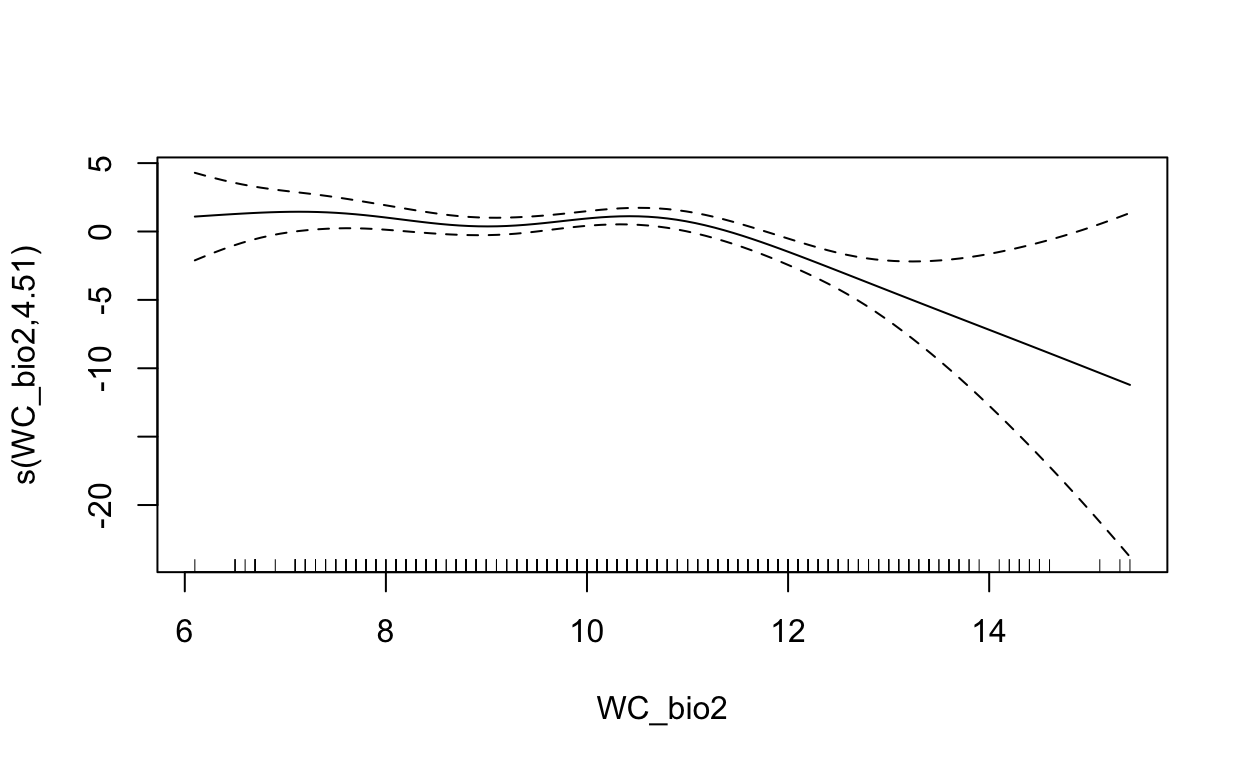
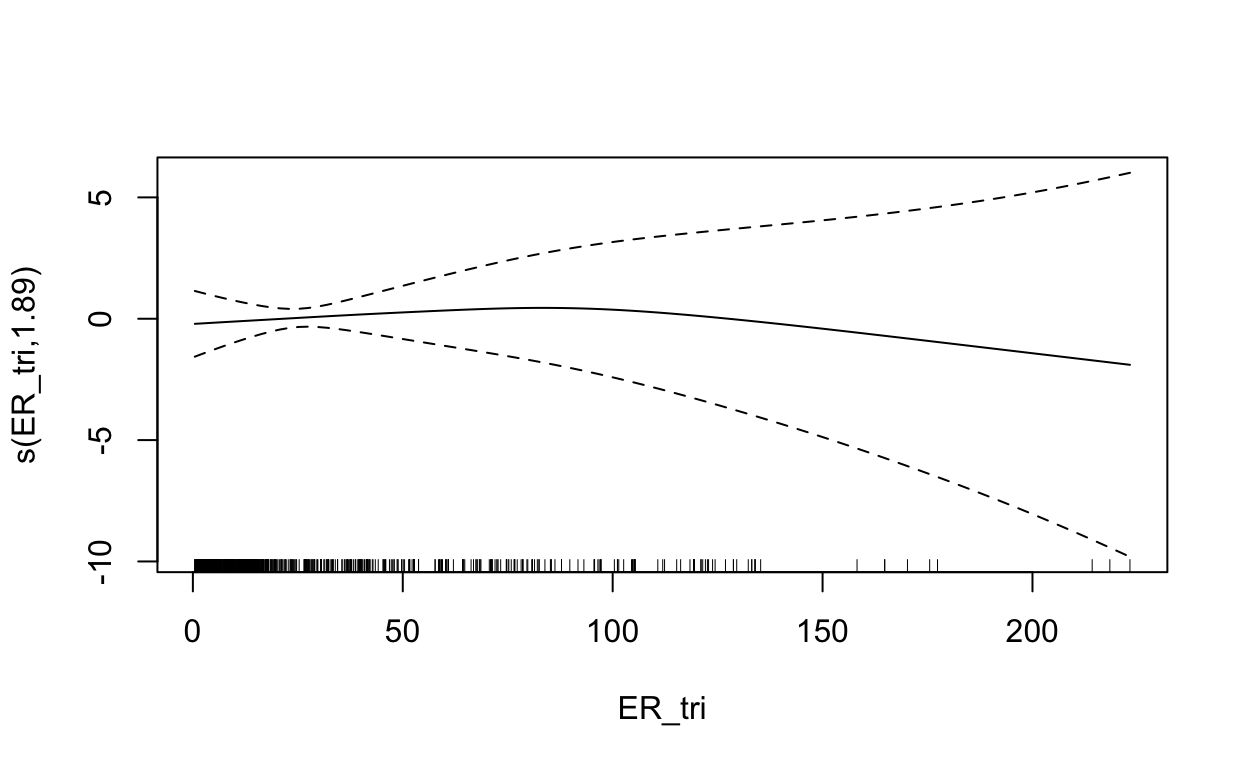
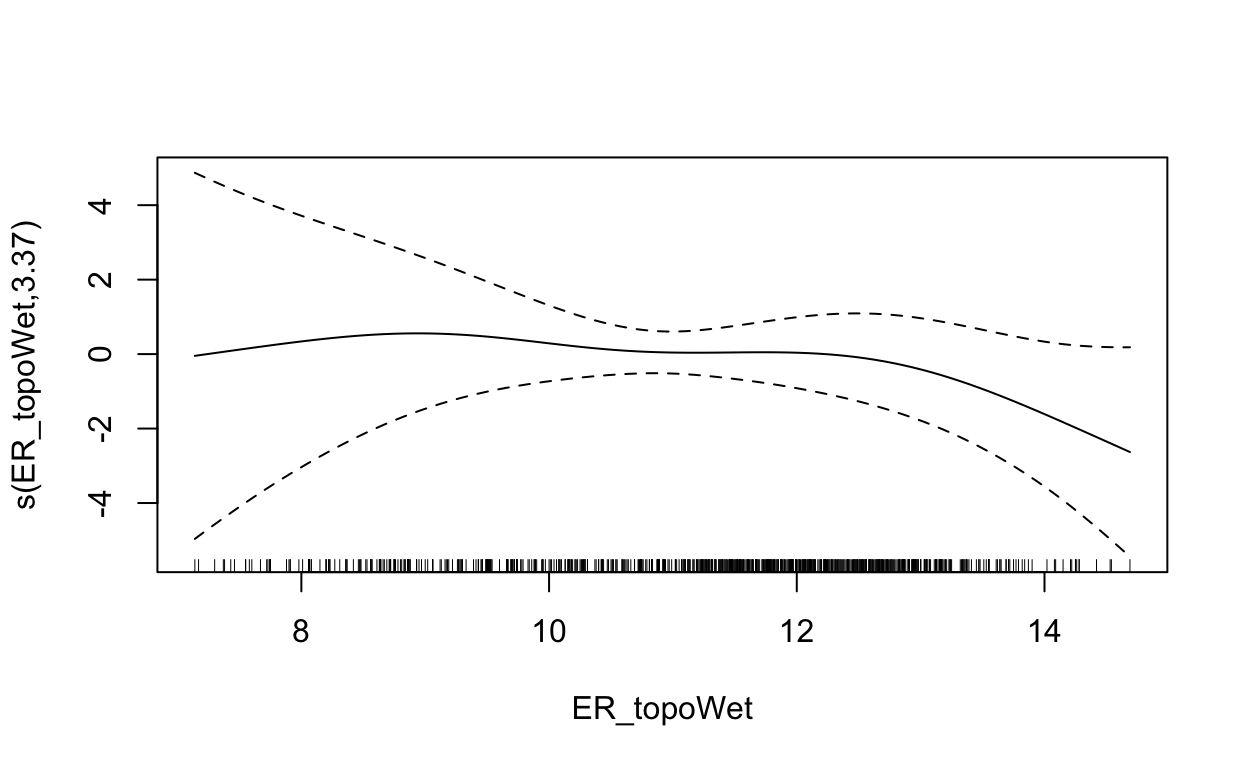
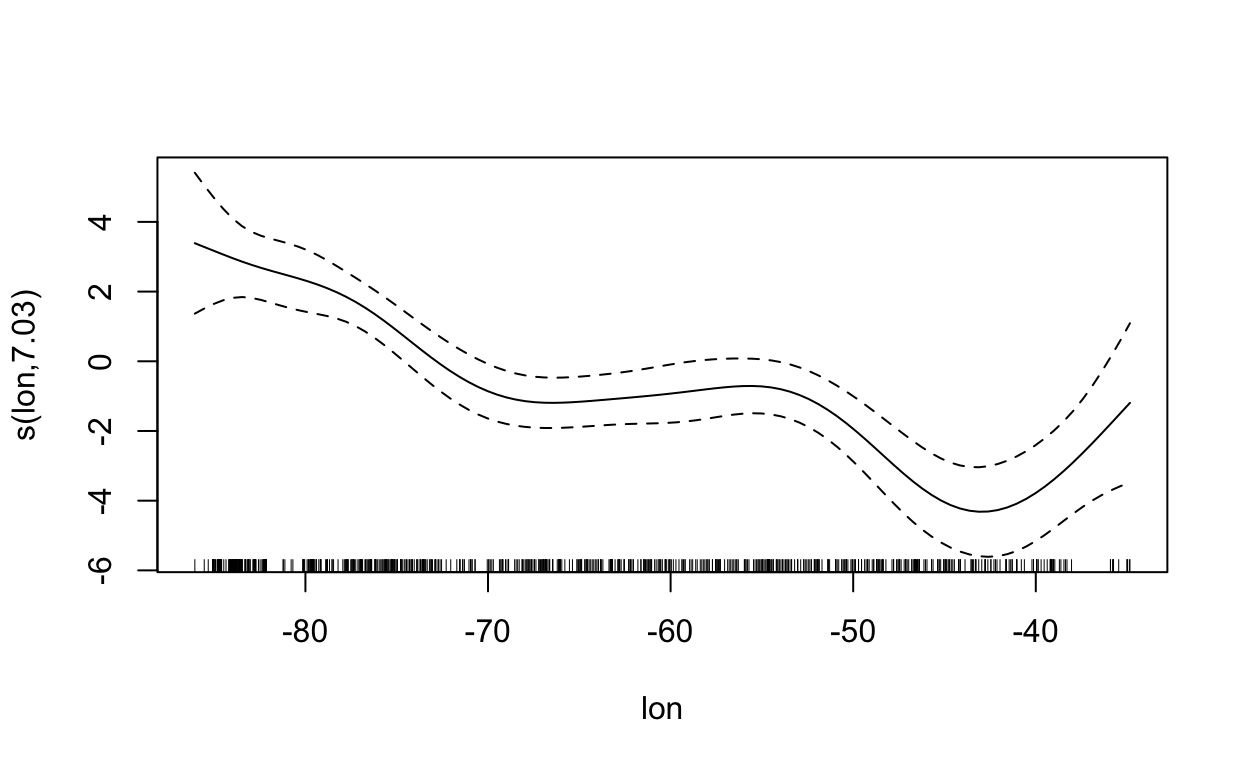
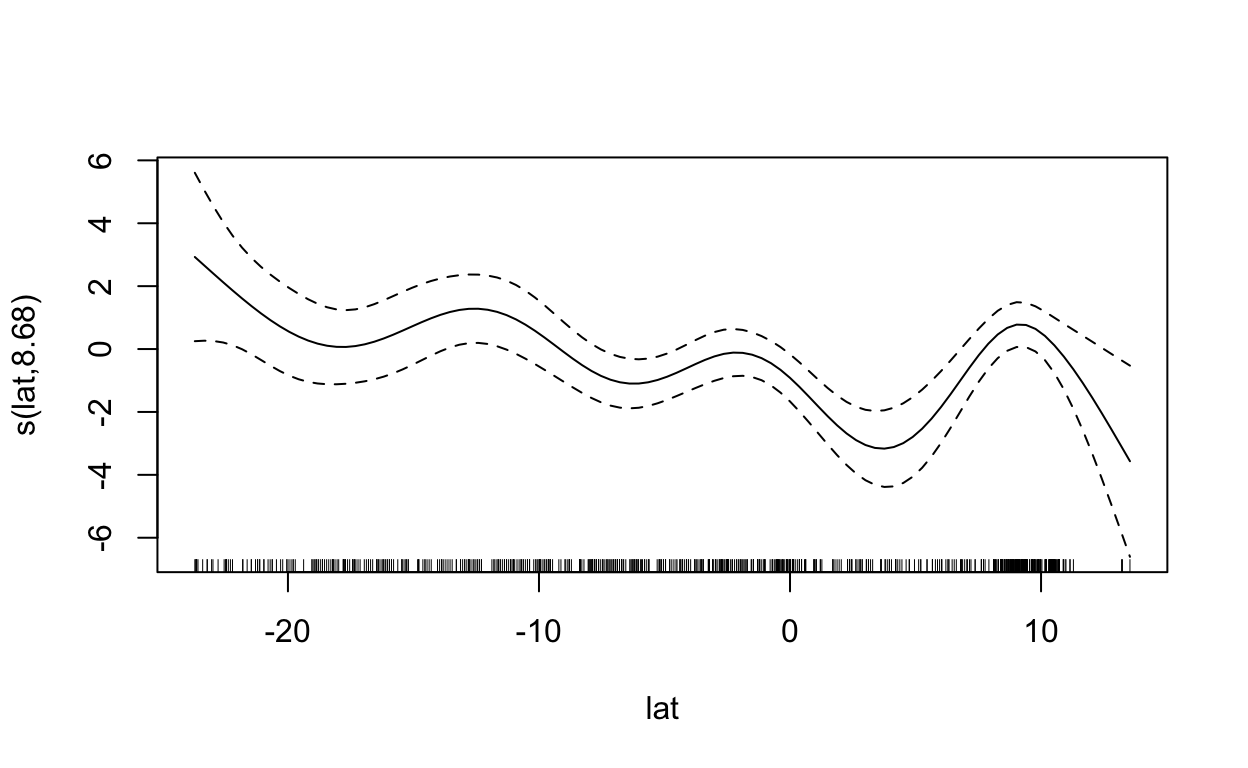
2.5 Maxent (Maximum Entropy)
Maxent is probably the most commonly used species distribution model (Elith 2011) since it performs well with few input data points, only requires presence points (and samples background for comparison) and is easy to use with a Java graphical user interface (GUI).
# load extra packages
librarian::shelf(
maptools, sf)
mdl_maxent_rds <- file.path(dir_data, "mdl_maxent.rds")
# show version of maxent
if (!interactive())
maxent()
This is MaxEnt version 3.4.3 # get environmental rasters
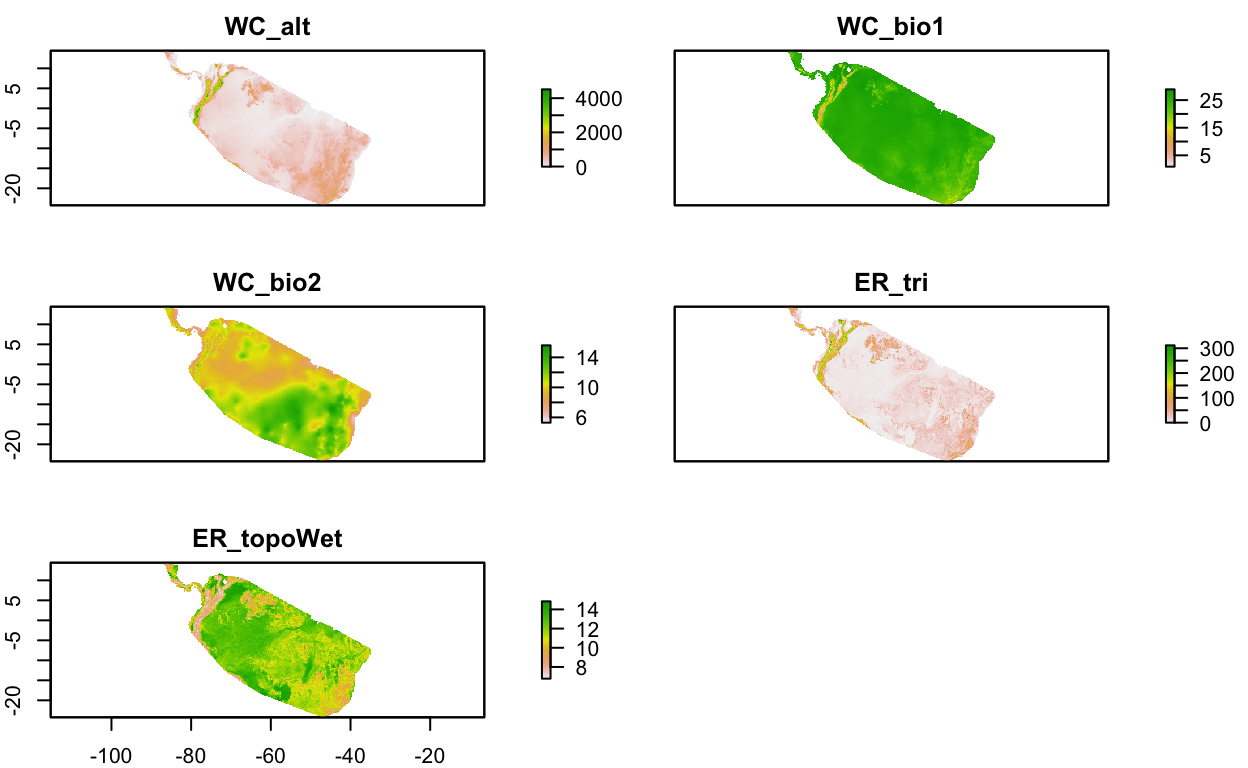
# NOTE: the first part of Lab 1. SDM - Explore got updated to write this clipped environmental raster stack
env_stack_grd <- file.path(dir_data, "env_stack.grd")
env_stack <- stack(env_stack_grd)
plot(env_stack, nc=2)
# get presence-only observation points (maxent extracts raster values for you)
obs_geo <- file.path(dir_data, "obs.geojson")
obs_sp <- read_sf(obs_geo) %>%
sf::as_Spatial() # maxent prefers sp::SpatialPoints over newer sf::sf class
# fit a maximum entropy model
if (!file.exists(mdl_maxent_rds)){
mdl <- maxent(env_stack, obs_sp)
readr::write_rds(mdl, mdl_maxent_rds)
}
mdl <- read_rds(mdl_maxent_rds)
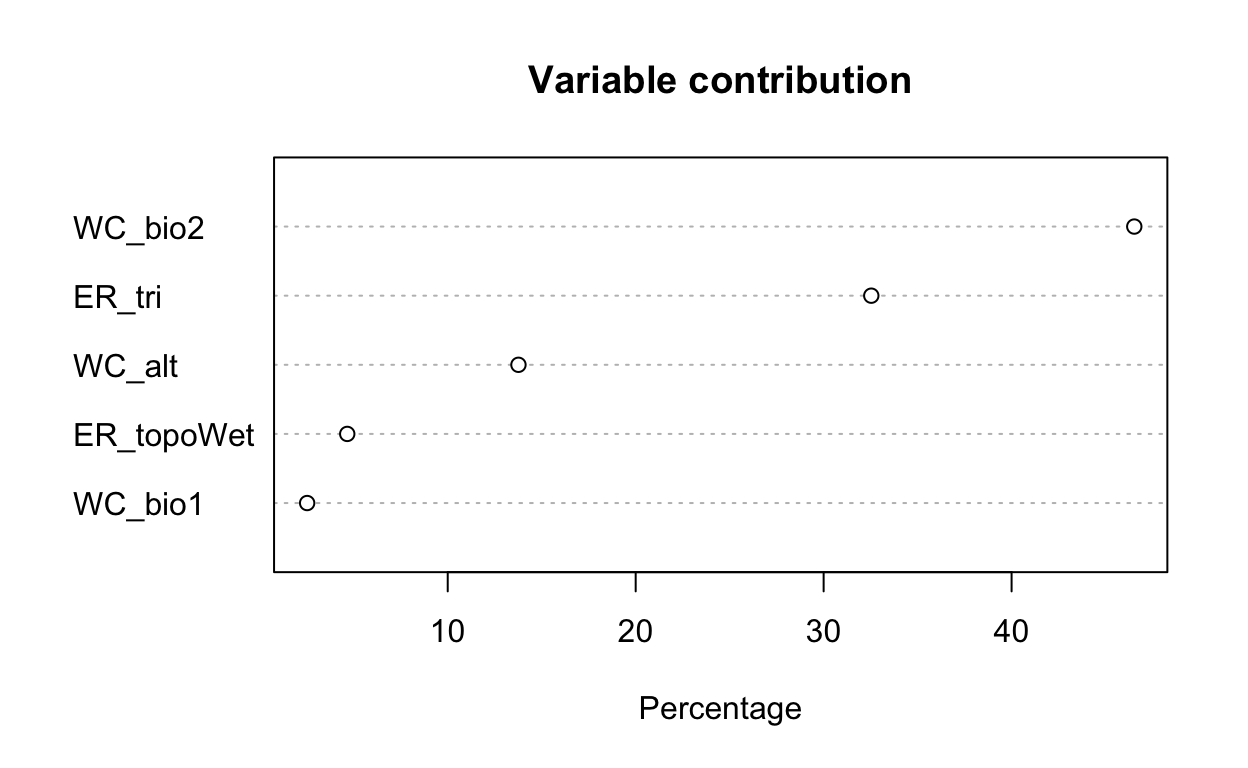
# plot variable contributions per predictor
plot(mdl)
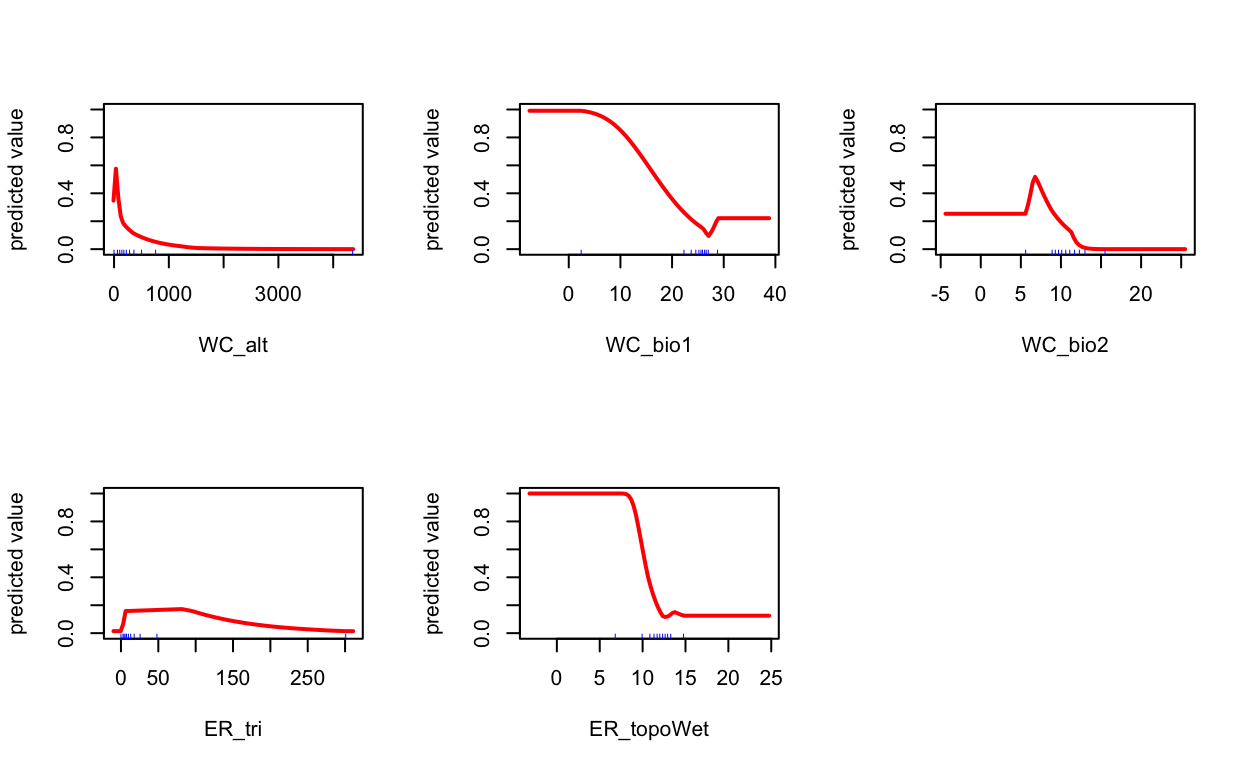
# plot term plots
response(mdl)
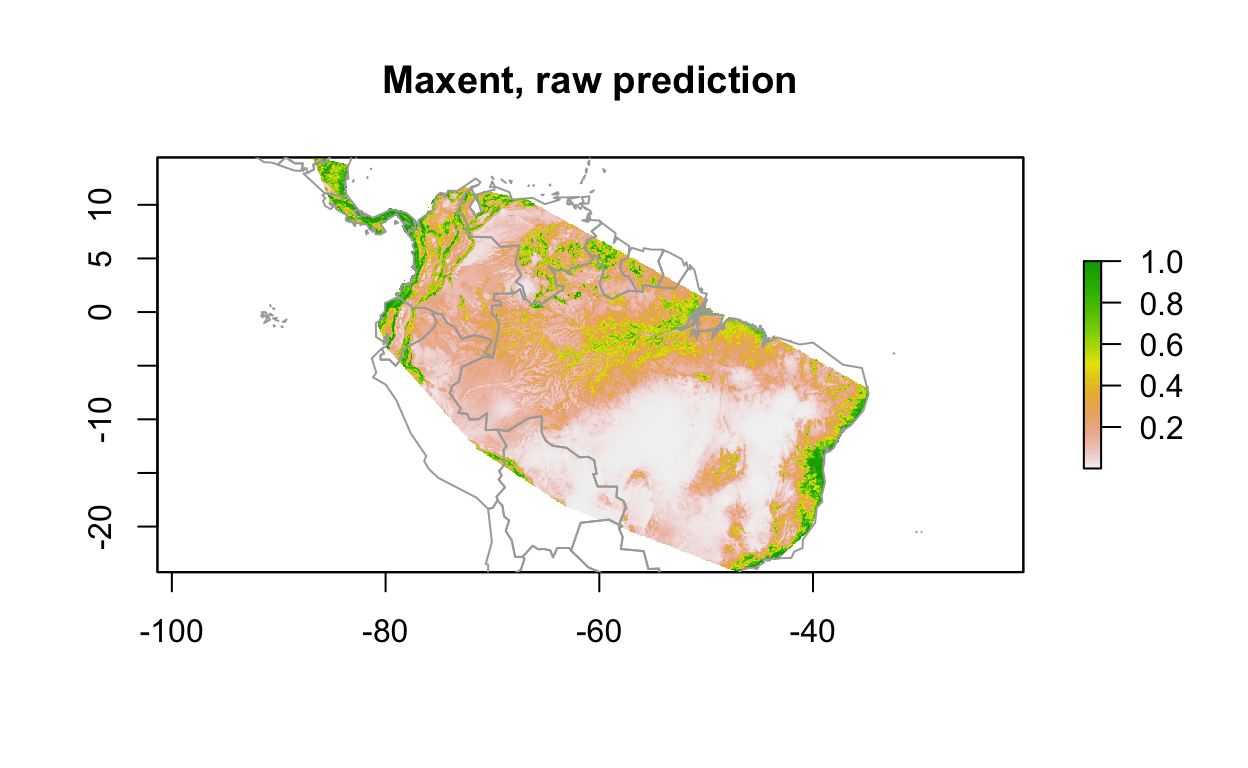
# predict
y_predict <- predict(env_stack, mdl) #, ext=ext, progress='')
plot(y_predict, main='Maxent, raw prediction')
data(wrld_simpl, package="maptools")
plot(wrld_simpl, add=TRUE, border='dark grey')
Notice how the plot() function produces different outputs depending on the class of the input object. You can view help for each of these with R Console commands: ?plot.lm, ?plot.gam and plot,DistModel,numeric-method
Next time we’ll split the data into test and train data and evaluate model performance while learning about tree-based methods.